So you’ve got your shiny new AWS account and now you want to start launching
some resources. Your account comes with a default VPC so you can just launch
your resources in there and you’re good to go right? Right‽
If you’ve ever started poking around with a brand new account, then you know
it’s not that easy. You may eventually throw an Elastic IP on an EC2 instance so
now you can connect to it and it can connect to the Internet. Now, of course,
you’ve just opened up your network.
Introducing public/private network architecture
You can separate systems that shouldn’t be available from the public Internet
from systems that can access it by using both public and private subnets. Your
private systems can still access the Internet if needed.
Some benefits of this architecture are:
Public subnets allow resources to be directly accessible from the Internet
Private subnets preventing resources from being directly accessible from the
Internet
A NAT Gateway can allow resources in a private subnet to connect to the
Internet or other AWS services
Additional subnet types can be added for additional security or connectivity
Great! How do I do it?
You can set up a simple public/private network architecture on AWS with a VPC
that has enough IP addresses to split across two or more availability zones (I
recommend three!). Create two subnets in each availability zone, one each for
public and private resources. When determining your CIDR ranges, consider what
resources you need to be available directly from the Internet; this will
determine the size of your public subnet. Your public subnet will likely be much
smaller than your private one in terms of address space.
Public subnets
Public subnets will need an Internet Gateway to establish Internet connectivity.
You can use the main route table for all subnets, or a separate route table can
be created for each. The routing table should contain the following two routes
at a minimum:
Destination
Target
0.0.0.0/0
Internet Gateway for the VPC
VPC CIDR
local
If you’re using the default routing table, it should be configured like this
already.
Private subnets
If your private resources don’t need to access the Internet, then they can share
a single route table with the following configuration:
Destination
Target
VPC CIDR
local
If your private resources do need access to the Internet, you’ll need to add one
or more NAT Gateways in the public subnets. While each of your subnets can use a
single gateway, and therefore route table, this can lead to a single point of
failure.
A single NAT gateway may be fine for a non-production environment, but for high
availability you should have one per availability zone. This ensures that if an
availability zone goes down, your resources in the over availability zone(s)
will still operate. Multiple gateways will require one route table for each
private subnet.
Regardless of the number of route tables you end up with, they will each need
the following routes:
Destination
Target
0.0.0.0/0
NAT Gateway
VPC CIDR
local
Make sure to associate each route table with the appropriate subnet(s).
VPC Endpoints
When you try to connect to systems outside your VPC from the private subnet,
your traffic will flow through the NAT Gateway. This includes connecting to AWS
services such as S3 or SSM (Systems Manager). Connecting to these services and
sending your data over the Internet introduces security risks. These risks can
be avoided with VPC Endpoints.
VPC Endpoints allow resources in your VPC to access services over
PriavteLink. When you create an endpoint for an AWS service, DNS
requests will resolve to the private IP addresses. Therefore, there’s no need to
configure any routes to use the VPC endpoint.
If you plan on using SSM to manage your instances, you wil need to configure VPC
endpoints. At a minimum, you will need an endpoint for
com.amazonaws.region.ssm. For some features, like Session Manager, you will
also need endpoints for com.amazonaws.region.ec2messages and
com.amazonaws.region.ssmmessages.
Putting it into code
There are many infrastructure as code (IaC) options that can support
implementing this architecture, including Amazon’s own
CloudFormation and Cloud Development Kit (CDK). Here,
we’ll be using Terraform, a popular open source IaC tool.
We could create each resource individually using the AWS provider.
However, Amazon has published a number of modules to help create
common sets of resources. This includes vpc anc vpc_endpoints. We can use these
in our main.tf to setup everything we need.
From here, you could run terraform plan to see all the resources that would be
created, and terraform apply to create them.
Just the beginning
This is really just the beginning to the options available for network
architecture in the cloud. You could have additional subnets that have specific
designations, such as for databases or connecting to an on-prem hosted system.
If you’re just getting started with networking in the cloud, though, this should
be a good starting point.
I was recently working on a database migration from
AWS
Amazon Web Services
GovCloud
to AWS Commercial. We had a production database that was initially launched in
GovCloud despite not being a
FISMA
Federal Information Security Management Act
High workload. Other pieces of
the stack had already been migrated, and the database, the most difficult piece
to move, was the last piece remaining.
Our options were more limited as we were going across partitions and AWS
services can’t communicate across partitions. This includes IAM trust
relationships. Both the source and destination were RDS Postgres clusters.
After reviewing a number of options, replication using pglogical
was an easy choice. To minimize downtime and allow for easier rollback, we opted
to use bidirectional replication. This is where each cluster replicates changes
in both directions. In our case, the GovCloud cluster would replicate changes to
the Commercial cluster, and vice-versa.
What is replication?
Replication is the process of creating and maintaining one or more copies of a
database. These copies are kept in sync with each other. Replication can be used
to achieve high availability, improve performance, provide backups, allow for
faster disaster recovery, and enable geo-distribution.
There are different types of database replication, including:
Physical replication: The entire database is replicated, including all
data and schema objects, at the file system level. Binary replication is a
form of physical replication.
Logical replication: Only selected tables and data changes are replicated
to the secondary database.
Synchronous replication: Changes made to the primary database are
replicated to the secondaries immediately. The transaction on the primary is
not committed until it has been successfully replicated to all secondaries.
This is useful to eliminate race conditions caused by replication lag, but can
have a significant performance impact.
Snapshot replication: A snapshot of the primary database is taken and
replicated to the secondary database at a regular interval. This type of
replication is useful for maintaining a point-in-time copy of a database.
Unidirectional vs. bidirectional
Unidirectional replication creates copies of a single, primary database to one
or more replicas. These replicas could be used as read-only servers to help
distribute database load, or one of them could be promoted if the primary goes
down or requires maintenance. Unidirectional replication is the most common
replication configuration.
Bidirectional replication creates copies in each direction. Each database is
replicated to the others and vice-versa. This can create conflicts, especially
if one or more nodes fall behind. Bidirectional replication is useful for
geo-distribution, improved write performance by distributing queries, and
migrations where you need the ability to quickly roll back without data loss.
How many nodes?
The total number of nodes that you’ll need in your database cluster depends on
your needs, and this is further complicated by
DBaaS
Database-as-a-Service
providers
that often have their own replicas. In fact, if you’re using a DBaaS provider,
you may not need to configure replication unless you’re looking to migrate your
database.
In general, the recommended number of nodes for ongoing replication is an odd
number of three or more. The importance of an odd number is that clusters can
participate in elections, where each node gets a vote. An odd number of nodes
helps to avoid a tie that could result in data loss. These elections can be
initiated in the case of a conflict during replication, when determining if a
node is down, and promoting a node to primary.
How does pglogical support bidirectional replication?
pglogical is a PostgreSQL extension that provides logical replication
capabilities. It supports both unidirectional, and bidirectional replication, as
well as replication between different versions of PostgreSQL. This makes it a
great option for database migrations.
There are some limitations to replication with pglogical (not an exhaustive
list):
Sequences require additional configuration and are only updated periodically
To set up replication using pglogical, you first need to install the pglogical
extension on all databases that’ll be participating in replication. You should
be able to find pglogical (it may be listed as “pg_logical”) in your systems
package manager. For Ubuntu, you can use the following command to install
pglogical for PostgreSQL 14:
apt install-y postgresql-14-pglogical
Once installed, you’ll need to configure PostgreSQL to load the extension and
use logical replication. This can be done by configuring the following settings
in your postgresql.conf:
Configure pglogical for unidirectional replication
Before we jump into bidirectional replication, let’s get unidirectional
replication setup. Since we’re trying to migrate a database, we’ll setup this up
on two nodes called “source” and “destination.”
You will need to create a replication user on each node and that user will
require the superuser privileges. For this example, we’ll connect to each node
using basic authentication (username and password) as this is the only option
available on AWS without being able to use IAM roles.
Connect to the source database and load the extension:
CREATEEXTENSIONpglogical;
Now add this node to pglogical. This will need to match the settings we use when
subscribing from the destination.
When you load pglogical, it creates three replication sets:
default: All statements for all tables in the set.
default_insert_only: Only INSERT statements for tables in the set. Primarily
used for tables without primary keys.
ddl_sql: Replicates DDL commands. See the section on DDL below.
We’re going to be using the default replication set, which should be sufficient
for most situations. You can also define your own replication sets. See the
pglogical documentation for more information on that.
We can add all existing tables to the default replication set with a single
command, adding any schemas that you want to replicate to the array:
Our source node is now ready to replicate data to any subscribers! Before we’re
done with the source, you’ll need the database schema to exist on the
destination. If you already have a SQL file or some other way of building it on
your destination, then great! If not, you can grab it from the source using
pg_dump (make sure to add any necessary connection flags):
pg_dump --schema-only databasename > schema.sql
Alternatively, you could add synchronize_structure := true to the
create_subscription call below. However, while pg_dump has additional
options that allow you to dump specific schemas and tables,
synchronize_structure will always synchronize all schemas and tables.
Okay, now we’re done with the source (for now). On the destination, start by
adding the schema. If you used the pg_dump command above, you can feed that file
to the psql client:
psql databasename < schema.sql
Now, let’s repeat the first few steps from source. We’re going to load the
extension and add the node:
Since we’re only setting up unidirectional replication at this point, we don’t
need to setup any replication sets. We do, however, need to subscribe to the
source database:
We set forward_origins to “{}” which means we only want data replicated from
the node in which it originated. The default is “{all}”, which means we don’t
care which node the data originated from, we just want it. This can be useful in
unidirectional replication with multiple nodes, but it can cause issues with
bidirectional replication. This setting is especially important when replicating
[sequences][sqquences].
Data should now begin replicating from the source to the destination. You can
monitor progress using the pg_stat_replication view.
Configure pglogical for bidirectional replication
Now that our destination has caught up, let’s start replicating data the other
way. We’re going to be repeating some steps from above, just on different nodes.
To start, let’s add our tables from the destination to the default replication
set (I did say “yet”). Once again, you can add all the schemas to be replicated
to the array.
And that’s it! We’ve just setup bidirectional replication between two PostgreSQL
databases. Like anything else though, it’s not quite that simple.
Let’s talk sequences
Sequences, sometimes called autoincrement columns, are commonly used to create
unique ids as a primary key. On the backend, the database keeps track of the
current value for the field. When a new record is added, it uses the latest
available value and increments the counter.
This gets complicated when you have multiple places that writes can happen. Not
only do new records need to be synced, but also the current state of the
counter. Two records could be written to different nodes in close enough
proximity that they end up with the same id.
pglogical handles sequences separate from tables. You need to explicitly add
sequences to the replication set in addition to the tables. This can be done by
adding all sequences at once:
When new nodes subscribe to the replication set, it will sync the sequences and
create an offset for each node. This way, there won’t be any overlap. The
sequences are then re-synced on a periodic basis.
An example
Let’s say we have a table called people with columns id and name. id is a
sequence column. This table is empty at the time that we setup replication, so
the sequences have been synced before any data has been added.
If we create our first record in the source database, we’ll get something like
the following:
id
name
1
James
If we then create our second record, but this time on the destination database,
we get something similar to:
id
name
1
James
1001
Naimothy
You can see that the record we added to the primary was replicated over and we
have a new record with the id 1001. This gives us some breathing room before we
would have to deal with a sequence collision.
A sequence is a database object in PostgreSQL that’s used to generate unique
numeric identifiers. Sequences are often used to generate primary key values for
tables. When you create a new table, you can specify that the primary key column
should use a sequence for its default value.
If you want to manually trigger a sync of sequences, you can use the following
to synchronize a single sequence:
DDL, or Data Definition Language, is a subset of SQL for creating and modifying
objects in a database schema. This includes statements such as CREATE, ALTER,
and DROP. These statements aren’t replicated by pglogical unless it is
explicitly told to do so.
If you want to replicate a DDL statement, such as ALTER TABLE, you’ll need to do
so using the replicate_ddl_command function. For example:
This will add the column to the table locally, then add it to the ddl_sql
replication set for any subscribers.
How to test it out
In order to test these configurations, I put together a
docker compose file. It launches two containers running PostgreSQL
with pglogical installed and loaded. A container with pgAdmin, a
web-based management interface, is launched and exposed over localhost port
8080.
I have made this available on GitHub for anyone who’d like to give it a
try. The default credentials are documented in the README along with other
details.
This site is built using Jekyll and hosted on GitHub Pages.
I’ve been using this setup for some time, since switching from a Drupal site
(which was overkill for this small blog and the little traffic it receives) and
paid hosting. Until recently, I used the default setup on GitHub Pages which
uses jekyll 3.9.2. When I decided to hit the reset button, I saw that
Jekyll 4.0.0 was released in 2019 (nearly four years ago!) and with the release
of 4.3.0, the 3.9.x releases were officially moved to security updates
only.
GitHub has, unfortunately, made no mention of updating the supported version
used for GitHub Pages. However, at its core, Pages is just a static hosting
service with some support for building from Jekyll. I opted to move forward
using the latest version of Jekyll, knowing that I would have to handle building
the site myself.
Jekyll 4
Jekyll 4.0.0 was a complete rewrite of the codebase. This rewrite dropped
support for older ruby versions, removed dependencies that were no longer
maintained, and included a number of enhancements.
Some of the major enhancements in the 4.x releases:
Many improvements to caching
A new Sass processor
An updated markdown engine
Better handling of links
Configuration options for gem-based themes
Support for logical operators in conditional expressions
Support for Ruby 3.x
Support for CSV data
There’s much more, and of course all of the bug fixes and security updates
included in every release. Checkout the releases page for more
details.
Deploying Jekyll 4 on GitHub Pages
To deploy Jekyll 4 on GitHub Pages, you’ll need to use
GitHub Actions. GitHub Actions is a
CI/CD
Continuous integration and continous delivery
service that
allows you to automate tasks in your workflow. You can use it to build, test,
and deploy your code similar to other systems like Jenkins or CircleCI.
Workflows are configured in YAML files in the .github/workflows directory of
your repository. You can have multiple workflows, each of which can have one or
more jobs, which in turn contain one or more steps. For our purposes, we need
one workflow with two jobs, one to build the site and another to deploy it to
GitHub Pages.
For example, the workflow file for this site looks like this:
.github/workflows/deploy.yml
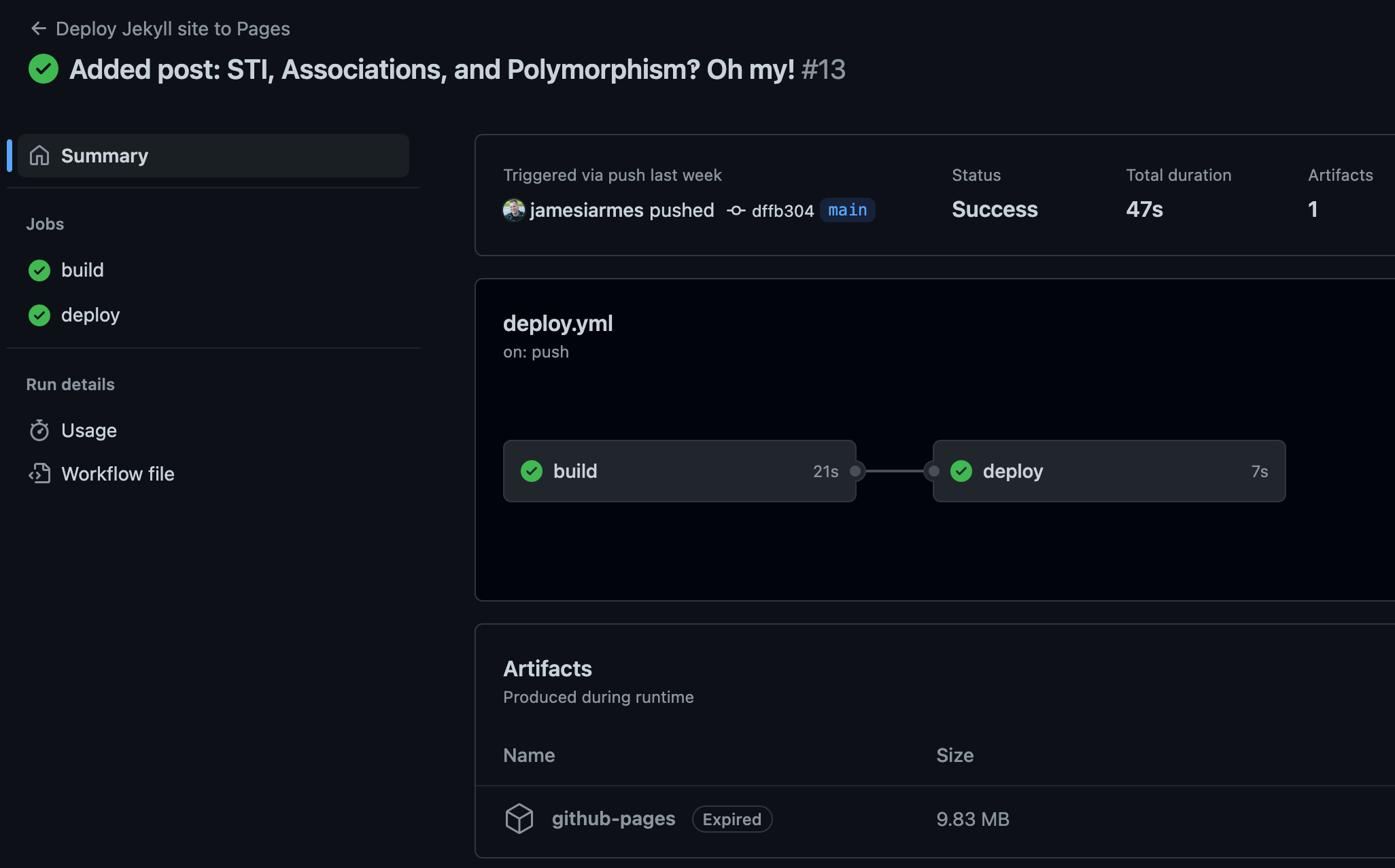
# This workflow uses actions that are not certified by GitHub.name:Deploy Jekyll site to Pageson:push:branches:main# Allows you to run this workflow manually from the Actions tabworkflow_dispatch:# Sets permissions of the GITHUB_TOKEN to allow deployment to GitHub Pagespermissions:contents:readpages:writeid-token:write# Allow one concurrent deploymentconcurrency:group:pagescancel-in-progress:truejobs:build:runs-on:ubuntu-lateststeps:-name:Checkoutuses:actions/checkout@v3-name:Setup Rubyuses:ruby/setup-ruby@v1with:bundler-cache:true-name:Setup Pagesid:pagesuses:actions/configure-pages@v2-name:Build with Jekyll# Outputs to the './_site' directory by defaultrun:bundle exec jekyll build --baseurl "$"env:JEKYLL_ENV:production-name:Upload artifact# Automatically uploads an artifact from the './_site' directory by defaultuses:actions/upload-pages-artifact@v1# Deployment jobdeploy:environment:name:github-pagesurl:$runs-on:ubuntu-latestneeds:buildsteps:-name:Deploy to GitHub Pagesid:deploymentuses:actions/deploy-pages@v1
Now, anytime I push a change to my main branch, the site is built and deployed
automatically!
For much of 2022 I was working on an open data classification tool built in Ruby
on Rails. Although initially developed to help classify emergency call data, the
tool could be used for any type of data, with some modification.
When describing a data set, the user uploads a CSV file and that file is parsed
to generate some basic statistics and get the list of headers. After mapping
fields from the data set to a common schema, the CSV is again parsed looking for
unique values that need to be classified.
Many open data platforms expose a public API that could be used instead of
uploading a CSV. These APIs would require more information and code for each
platform to get the same information as the CSV. However, this information could
be acquired more quickly and with far fewer resources. Using an API would also
allow for future updates to the data set.
My experience with Rails before this project was minimal. I could visualize how
I’d implement multiple data source types in general, but I need to learn how to
do it “the Rails way.” I’m not certain I accomplished that completely, but I did
learn some things about Rails models and associations along the way.
What is STI?
Single Table Inheritance (STI)1 is a design pattern in Ruby on Rails that
allows you to use a single database table to store multiple types of objects
that share some common attributes. This is accomplished by adding a type column
to the table that’s used to store the class name of each object.
For example, you might have a Person class that has a name attribute and a
type attribute. You could then create two subclasses of Person: Employee
and Student. In the database, all the Employee and Student objects would
be stored in the same table as Person objects. The type column would be used
to differentiate between the different types of objects.
Subclasses can share any number of attributes (as long as the type remains the
same) as well as have their own attributes. Each attribute will be added as a
column on the table, which can make it difficult to scale if you have many
subclasses with differing attributes. This is important to consider when
deciding to implement STI over MTI (Multiple Table Inheritance).
What are associations?
Associations are a way to define relationships between Active
Record models. These relationships allow you to specify how one model is related
to another, and how the models should interact with each other.
There are several types of associations that you can use in Rails:
belongs_to: used for relationships where the current model will store the
reference to a related model. For example, a Profile model that belongs_to
a User.
has_one2: used for one-to-one relationships where the related model includes
a reference to the current model. For example, a User model that has_oneProfile.
has_many2: used for one-to-many relationships where the related models
include a reference to the current model. For example, a User model that
has_manyNotifications.
has_and_belongs_to_many: used for many-to-many relationships and uses a
junction table to store the references. For example: an Author model that
has_and_belongs_to_manyBooks.
What are polymorphic associations?
Polymorphic associations allow a model to belong to more than one
other model using the same association. This is done by adding a type column to
reference the model, along with the standard id column. For example, you could
have a Comment model that can belong to either a Post or a Product:
With this association, you can use call .commentable on a comment to get the
comment’s parent, regardless of whether it is a post or product.
Why?
I opted to use STI to represent the data source models, which would all inherit
from DataSource. To begin with, there’d be two children: CsvFile and Socrata (an
open data platform). There are a few reasons for the decision3:
The number of shared fields between data sources is likely to be high, but
split between two types: file sources and API sources.
Does not increase database complexity with each new data source.
Extensibility and modularity: data sources could be packed as gems and
contributed by third-parties.
Single table inheritance lets you separate logic without repeating code or
complicating the database schema. Polymorphic associations make this pattern
even more powerful. However, it can also result in large tables with lots of
empty columns. If you expect your child models to differ significantly in their
field, you should consider a different implementation.
Yes, I know what else STI stands for, but I’m not going to repeat “single
table inheritance” seven times. ↩
These associations also have a through option that uses an additional
model in the middle. ↩↩2
If I come to regret this decision, you can expect a post titled
“Refactoring your way out of STI.” ↩
I know that Macs are very popular in the engineering community, but I have
always preferred some flavor of Linux for my local system. Throughout most of my
career I’ve used either Kubuntu or Fedora KDE Spin
(can you tell which desktop environment I like). I’ve played around with other
distros in the past, but I’ve always found these two to be the most stable for
my daily driver.
When I moved into civic tech, I had to dump Linux and move to macOS because it’s
easier to manage for compliance purposes. It’s been an adjustment, and it’s not
all bad. For the most part, I don’t run into any large hurdles that would impede
my everyday work.
There are little things, though:
Installing dependencies for certain gems or older Ruby versions
Some commands work differently compared to Linux (a consequence of being
BSD-based)
No native docker
OS version updates breaking software
Delays in receiving security updates
No separate highlight+middle-click clipboard (my most missed feature of KDE)
There more, but I think you get my point. And sure, I can deal with it, but why
should I? What this all comes down to is, I miss running Linux. I’ve tried
various methods in the past of replicating the experience with virtualization;
including VirtualBox, Parallels Desktop, and QEMU. They all fell short either in
performance or functionality, or most often both.
I recently ran into UTM, a system emulator and virtual machine system for
macOS. It supports both Intel and Apple Silicon, though for my purposes I only
need Intel, and Windows, Linux, and macOS guests. It sounded promising, so I set
out to create a Fedora 37 KDE VM (virtual machine). I haven’t used it much yet,
but wanted to capture my experience some of the issues I ran into in the event
that others may find it valuable.
Installing UTM using homebrew
Before we begin, I want to share the specs for my personal Mac that I used to
set this up:
MacBook Pro 2019 16-Inch
2.6 GHz 6-Core Intel Core i7
Intel UHD Graphics 630 1536 MB
16 GB 2667 MHz DDR4
macOS 13.0.1
Homebrew 3.6.13
I used Homebrew to install the latest version of UTM (4.0.9
currently). You can also download a DMG from the UTM website or install it from
the App Store. The App Store version is an official release but does cost
$9.99USD, which goes to fund development.
If you are using Homebrew, you can install UTM by running the following command
in your terminal:
brew tap homebrew/cask
brew install utm --cask
You should now be able to run UTM from Spotlight.
QEMU or Apple Virtualization Framework
There are two ways to run virtual machines on Intel Macs: QEMU and
AVF (Apple Virtualization Framework). I won’t be covering emulation or
Apple Silicon here.
QEMU is an open source emulator that can be used to run a number of guest
operating systems and architectures. It is not macOS specific and is available
for multiple platforms.
AVF is a macOS-specific virtualization platform that allows macOS to run a
variety of guest operating systems. It also supports hardware-assisted
virtualization, which can make it faster and more efficient than QEMU. AVF also
supports virtual networking and storage, allowing you to create more complex
virtual networks.
UTM supports both of these options; however, the AVF option is listed as
experimental. With this in mind, I initially started with QEMU. After taking the
time to setup a basic environment, I ran into an issue with directory sharing
which led me to try AVF. Your mileage may vary, but I found that AVF performed
better and I did not run into the same sharing issue.
Creating the virtual machine: Take one
Before we get into the details, I’d like to share the specs for the Virtual
Machine I created:
Linux operating system
8 GB memory (8192 MB)
64GB Storage
I used an ISO of Fedora 37 KDE Plasma Desktop and setup a directory share for my
IdeaProjects directory. I left all other settings with their default values.
I mentioned in the previous section that I started by using QEMU. This is the
default and requires no additional configuration.
I went through the normal install process and waited for it to complete. After
installation, I had to shut the VM down to remove the virtual device for the
ISO. I started the system and set out to set up a basic development environment:
Install any package updates
Install the Snap backend for Discovery
Install the JetBrains Toolbox
Install IntelliJ IDEA
Mount the shared directory
Open a project from the shared directory
I crossed out that last one because of the issue I alluded to earlier.
Arguably, I should have started by trying to mount the shared directory right
after installation, but hindsight is 20/20. I could mount the share without
issue by following the documentation:
mkdir$HOME/IdeaProjects
sudo mount -t 9p -otrans=virtio share $HOME/IdeaProjects -oversion=9p2000.L
Listing the contents of $HOME/IdeaProjects listed all my projects just as I
expected! With one exception, they were owned by 501:games. Obviously this was
a UID and GID mismatch between the host and the guest. The documentation
suggested I should be able to run sudo chown -R $USER $HOME/IdeaProjects, but
this led to a permission denied error for every file and directory. A quick
search showed that this was not an isolated issue which led others to use the
SPICE agent with WebDAV over the default of VirtFS and the 9p filesystem.
At this point I realized that my CPU fan had been running on high the entire
time the VM had been up. I had also noticed that the system did have some
delayed response times, especially when moving windows. I opted to shut down the
VM and try AVF; perhaps the purported performance improvement would be a
reality.
Once more, with feeling
For my second attempt I made one change to the specs: I checked the box next
to “Use Apple Virtualization”. That’s the only change required to use AVF. UTM
takes care of everything else under the hood.
I noticed one difference immediately. On the QEMU system, it opened in a smaller
window when I started the VM, regardless of what settings I had set before I
closed it. This time the window opened much larger, taking up most of my
desktop. The default resolution was also higher.
Installation completed the same as before. I noticed while waiting for
installation to complete that the pause button for the VM was available. It had
been grayed out on the last attempt.
After installation, I removed the ISO device, started the machine, and proceeded
to repeat the steps I followed the first time around. The CPU fan started up
when I launched the VM, but died down shortly after and I didn’t notice any
delays like I had before.
When it came time to mount the shared drive, I had to pass different parameters
to the command:
mkdir$HOME/IdeaProjects
sudo mount -t virtiofs share $HOME/IdeaProjects
This worked without issue and once again listing the contents shows the projects
I expected. This time, however, the content was all owned by the current user!
I went on to open a project in IDEA, a simple Rails app. The project opened and
indexed as normal. The indexing process didn’t appear to take any longer than
usual, which would have pointed to a disk performance hit from directory
sharing.
A word about Wayland
Fedora 37 KDE uses the Wayland window system by default. Wayland is a
replacement for X11, but as it’s a different protocol there’s bound to be
compatibility issues. One such is copy and paste between host and guest.
There is currently an open bug with Fedora to address this issue,
but it may affect other distros as well. For now, if you need clipboard sharing
and you run into issues with Wayland, you can use X11 instead. On Fedora KDE,
X11 is installed by default and you can switch to it from the login screen.
Next: Trying out multiple displays.
One of the biggest issues I’ve run into in the past with virtualization on the
desktop is getting it to work with multiple displays. I usually work with three
displays (two external monitors and my Macbook display), so multiple monitor
support is important.
That’s for another time though. UTM seems to have potential, but only time will
tell if this could be a path to Linux as my daily driver once again.